openmp という、Fortran にコメント文の形でコマンドを挿入して
調べてみたら、何の事は無い gfortran に既に実装されていた。
こんな感じで簡単に使える。
tama@tama[114] cat test_1.f90 program omp use omp_lib write(*,*) 'before' !$omp parallel write(*,*) 'Hello OMP' !$omp end parallel write(*,*) 'after' end program tama@tama[115] gfortran43 -fopenmp test_1.f90 tama@tama[116] setenv OMP_NUM_THREADS 6 tama@tama[117] ./a.out before Hello OMP Hello OMP Hello OMP Hello OMP Hello OMP Hello OMP after6つ動作しているのが分かる。
ここ(京都大学) に、フォートランでの openmp の使い方もありました。
これで、数値モデルが書けない言い訳は無くなって行く。。。。
integer, parameter :: n=1000 integer :: i real :: x(n) !$omp parallel !$omp do do i=1, n x(i) = i end do !$omp end do open(unit=10, file="OUT") !$omp do do i=2, n x(i) = log(abs(cos(sin(x(i)+x(i-1))))) write(10,*) i, x(i) end do !$omp end do !$omp end parallel close(10) endこんなのを実行すると、出力 OUT には見事にばらばらの情報が書かれる。 setenv OMP_NUM_THREADS 4; ./a.out した結果は
cat -n OUT | xgraph -P -nlの結果 (を convert で jpg にしたもの) は
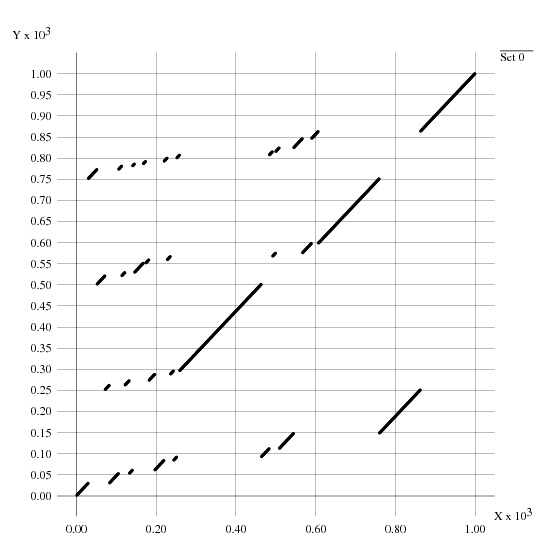
うーん、当り前! (2009.11) こういう時の安直な解決方法は、oedered を使って、do ループ内の出力順序を 決めることであるらしい。 (でも、下手をすると実行速度は落ちていくようだ。 他のスレッドが安直に待ってしまって実質1スレッド計算になる? 2009.12)
integer, parameter :: n=1000 integer :: i real :: x(n) !$omp parallel !$omp do do i=1, n x(i) = i end do !$omp end do open(unit=10, file="OUT") !$omp do ordered do i=2, n x(i) = log(abs(cos(sin(x(i)+x(i-1))))) !$omp ordered write(10,*) i, x(i) !$omp end ordered end do !$omp end do !$omp end parallel close(10)というように、!$omp do ordered 〜 !$omp end ordered で囲んだループ内の 出力文を !$omp ordered 〜 !$omp end ordered で囲んでやると、順番通り出力する。 (2009.11)
implicit none
integer, parameter :: N=1000, M=1000, NN=10, MAX_THREAD=10
integer :: i, j, i1, j1
real, allocatable :: x(:,:), y(:,:)
!$use omp_lib
character(len=1024) :: omp_num_threads
integer, external :: omp_get_thread_num
integer :: i_omp_num_threads, i_thread
integer :: ifile
character(len=1024) :: filename
integer :: neach, istart, iend
call getenv("OMP_NUM_THREADS", omp_num_threads)
read(omp_num_threads, *) i_omp_num_threads
write(0,*) 'OMP_NUM_THREADS ', i_omp_num_threads
!allocate( x(N,M) )
!allocate( y(N,M) )
neach = N/i_omp_num_threads
!$omp parallel private(i_thread, istart, iend, filename, ifile, i, j, x, y )
i_thread = omp_get_thread_num()
write(*,*) 'thread num = ', i_thread
istart = neach * i_thread + 1
iend = neach * (i_thread+1)
ifile = 10+i_thread
write(filename, '("OUT-", I1)') i_thread
allocate( x(neach,M) )
allocate( y(neach,M) )
do i=istart, iend
do j=1, M
x(i,j) = log(abs( sin(0.2*i*j)))
end do
end do
open(unit=ifile, file=filename(1:len_trim(filename)))
if( istart < NN+1 ) istart = NN+1
if( iend > N-NN ) iend = N-NN
do i=istart, iend
do j=NN+1, M-NN
y(i,j) = 0
do i1=-NN, NN
do j1 = -NN, NN
y(i, j) = y(i,j) + x(i+i1, j+j1)
end do
end do
y(i,j) = y(i,j) / ((2*NN+1)*(2*NN+1))
end do
write(ifile, *) i, (y(i,j), j=NN+1, M-NN)
end do
close(ifile)
!$omp end parallel
end
メモのトップへ